Unfamily confused by Windows by UTF-8 without BOM
Once in Windows, most of the text files were shifted JIS format.However, recently, UTF-8 format text files have been seen normally.It can be said that UTF-8 is becoming mainstream in the world.
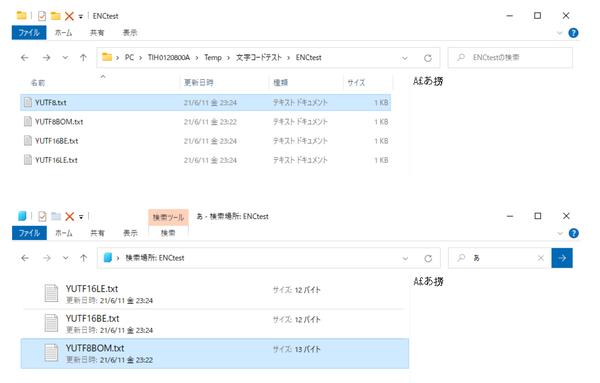
However, using UTF-8 on Windows has a little trouble.That is, the Windows Search used in the search column of Explorer does not support UTF-8 firmly.To be precise, Windows Search recognizes UTF-8 with "BOM" at the top of the file, accurately indexes, allows you to search for the full text of files, but UTF-8 without BOM cannot be indexed correctly., Full -text search for files is possible only with ASCII code, and full -text search cannot be performed in non -ASCII characters such as Japanese.
The text with the same content was encoded with UTF-8, UTF-8 BOM, UTF-16 Big Endians, UTF-16 Little Endians to make four files.If you search for "A" that should be included in any file, only the UTF-8 (without BOM) files will not be included in the search results.
UTF-8 format is becoming popular in the world, but BOM is not required, so there are many UTF-8 data without BOM.In addition, the notepad, which can be called the "standard text editor" of Windows, has now been used as a standard UTF-8 without BOM from "19H1" (May 2019 Update).We are doing so.Again, the UTF-8 Japanese text cannot be searched in Japanese in Windows Search.If you want to search for the full text, you have to save the file in the UTF-8 format with BOM.The story around here is confusing, so I would like to organize a little this time.
What is UTF-8 in the first place?
UTF-8 is one way to encode unicode characters.In Unicode, the text has a "sign position" (so -called code), and it is "encoding" to determine what kind of bit patterns to be stored in files.

UNICODE's "sign position" is described as "U+3042" using a hexadecimal expression.When writing this in a file, the "encoding" that determines what kind of bit patterns to make is a format such as UTF-8 and UTF-16.UTF is an abbreviation for "Unicode Transformation Format" in Unicode.There are other UTF-7 and UTF-32, but they are rarely found in file formats.
UTF-16be (Big Endian), UTF-16le (Little Endian), UTF-8 (no BOM), UTF-8 (with BOM) are displayed in the hexadecimal.PowerShell 7.In 1, the encoding of the file moves, so all files can be displayed correctly.By the way, Windows PowerShell 5.1, BOM-free UTF-8 cannot be displayed correctly
UTF-8 encodes the code position to 1 to 4 bytes.At this time, assuming access in byte units, arranged so that the top digit of the sign position comes forward.
Windows uses UTF-16 internally.The UTF-16 is a method for expressing one letter in 16bit, but now that a large number of characters are recorded in Unicode, it expresses some characters in two 16-bit characters (this is called Sarogate pair).
Microsoft calls the UTF-16 "UNICODE" (early Unicode was planning to put all characters around the world in 16bit).In the UTF-16, the Endian of the CPU will be affected because the characters are expressed in 16bits handled by the CPU.What is needed for this is BOM (Byte Order Mark).
BOM is encoded with the sign "U+Feff".By looking at this, it is possible to distinguish Endians.In Windows, UTF-16 (UNICODE) also uses Little endian because it is based on Little Endians.Some programs attached to Windows do not support Big endian UTF-16.For example, in the Explorer's preview area, Big Endian's UTF-16 cannot be displayed (but you can search).
In UTF-8, there is no difference in Endian because the encoding is determined to be able to handle data in byte.By specifications, BOM is not prohibited, but it is not required.If it corresponds to UTF-8 correctly, there is no problem even if there is a BOM, but if there is a BOM at the beginning of the file, there is a possibility that a problem will cause a program that expects 7bit ASCII.be.The BOM of UTF-8 is "EF BB BF" in the hexadecimal.
It may be difficult to distinguish between two-byte character code and UTF-8 before Unicode, such as the Japanese shift JIS.In some cases, you may not be able to judge either file from the beginning to the end.Perhaps because of that, Microsoft's software such as Excel accepts UTF-8 with BOM.
In other words, in the case of a text file, if there is a BOM of UTF-8, it will be judged as UTF-8, and otherwise it is estimated to be a shift JIS.It seems that Windows Search has the same mechanism.In the shift JIS, the "EF BB" at the top of the UTF-8 BOM is not assigned, and if the "text file" of the correct shift JIS does not include this code, it is estimated to be BOM of UTF-8.Because it is possible.

![10th generation Core i5 equipped 9.5h drive mobile notebook is on sale at 50,000 yen level [Cool by Evo Book]](https://website-google-hk.oss-cn-hongkong.aliyuncs.com/drawing/article_results_9/2022/3/9/4a18d0792cae58836b71b9f591325261_0.jpeg "10th generation Core i5 equipped 9.5h drive mobile notebook is on sale at 50,000 yen level [Cool by Evo Book]")



![[Amazon time sale in progress! ] 64GB microSD card of 1,266 yen and wireless earphone with noise canceling function of 52% off, etc.](https://website-google-hk.oss-cn-hongkong.aliyuncs.com/drawing/article_results_9/2022/3/9/c88341f90bab7fe3ce1dc78d8bd6b02d_0.jpeg "[Amazon time sale in progress! ] 64GB microSD card of 1,266 yen and wireless earphone with noise canceling function of 52% off, etc.")

