録り溜めたボイスメモをAI音声認識APIで一気にテキスト変換しよう
WAVファイルを音声認識してテキストに変換したところ
音声認識APIを使ってみよう
AI技術の進歩により音声認識の精度が向上している。これまでも音声認識の技術はあったものの精度が今一歩だった。そして個人ユーザーが気軽に活用できる感じではなかった。ところが、最近では、各社が競い合うように音声認識の精度向上に力を入れている。各社から発売されているAIスピーカーを積極的に活用している読者も多いことだろう。
そして、大きな点として、MicrosoftやGoogle、Amazonなど、各社が音声認識技術をWeb APIという形で提供している。簡単なプログラムを書くだけで、音声認識を利用できるのは大きい。手元に大量のボイスメモがあるなら、APIを利用して一気にテキスト化することができる。
プログラムを作らない解決策
なお、プログラムを作ることなく音声認識を使うこともできる。最も手軽なのは、Microsoft 365のWordを使う方法だろう。2020年8月25日以降、Microsoft 365のオンライン版のWordには音声認識の機能が提供されている。
利用の手順を簡単に紹介しよう。まず、ブラウザでMicrosoft 365のサイトを開いてログインする。新規Word文書を作成したら、画面上部の[ホーム]タブにあるマイクのアイコンを探そう。そしてすぐ右側にある[v]から「トランスクリプト」をクリックしよう。続いて「音声をアップロード」のボタンを押して音声ファイルを選ぼう。WAV/MP3/M4A/MP4などの形式のファイルを指定してテキストに変換できる。
Microsoft Speech to text APIを使おう
ただし、上記の方法ではブラウザを開いてファイルを指定するという手間がかかってしまう。録り溜めてある大量の音声ファイルを一気に変換したい場面ではプログラムを作るのが便利だ。
そこで、PythonからWeb APIを用いて音声認識を利用する方法を紹介しよう。プログラムから手軽に音声認識が利用できれば、大量の音声ファイルを一気に変換したり、何かしらのイベントに応じて自動的に変換処理を実行できるので便利だ。
なお、既に紹介したように、いろいろな会社が音声認識APIを提供しているが、今回はMicrosoftが提供しているCognitive Services / Speech Serviceの「Speech to text」を利用してみよう。これを利用することで手軽にWAVファイルをテキストに変換できる。原稿執筆時点では、1ヶ月あたり5時間まで無料で利用できる。

Azure Portalにサインインして音声サービスのキーを得よう
なおAPIを使うには、こちらからAzureのアカウントを作成する必要がある。アカウントを作成してAzure Portalサインインしよう。
そして、「+ リソースの作成」のアイコンをクリックしよう。Azureには数多くの機能が提供されているので、検索機能を利用して「音声」を検索しよう。次の画像のように音声が見つかったら、「作成」をクリックしよう。
そして、名前に「VoiceMemoConverter」、サブスクリプションに「Azure subscription 1」、場所に「(Asia Pacific) 東日本」、価格レベルに「Standard S0」、リソースグループを新規作成し選択したら「作成」ボタンを押そう。
そして「デプロイが完了しました」と表示されたら「リソースに移動」のボタンをクリックしよう。もし、ホームに戻ったなら「最近のリソース」に表示されている「VoiceMemoConverter」を選択しよう。
そして「基本」にある「キーの管理」をクリックしよう。
すると、APIを利用するためのキーが生成されるのでコピーして控えておこう。また「場所/地域」も指定が必要になるので、ここで表示される情報は参照できるようにしておくと良いだろう。
なお、より詳しい情報や画面が更新されてしまった場合には、マイクロソフトのドキュメントから、こちらを参照しよう。
プログラムを作ろう
Pythonのライブラリを使えば、MP3やM4Aなどさまざまな音声ファイルの変換も可能となるが、今回はプログラムを単純にするために、あらかじめ音声ファイルはWAV形式に変換してあるものとする。
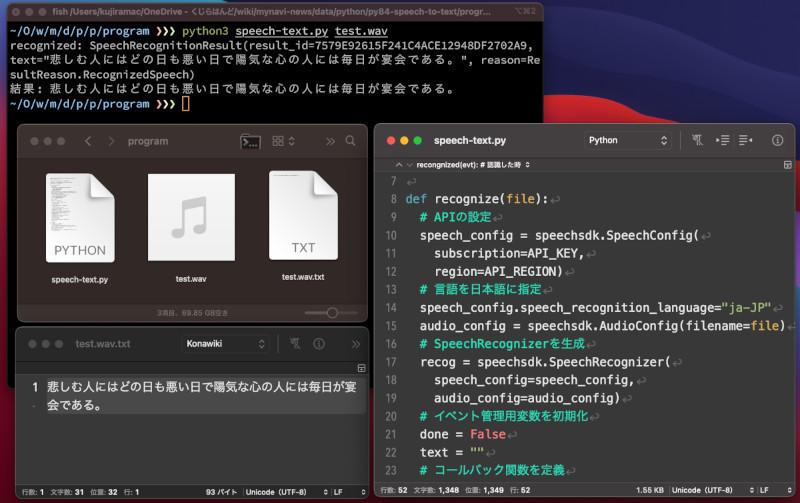
ここではWAVファイルを音声認識して「(元ファイル名).txt」という名前で保存するプログラムを作ってみよう。
最初に、必要なライブラリ「azure-cognitiveservices-speech」をインストールしよう。コマンドラインで以下のコマンドを実行することでWeb APIを使うためのライブラリをインストールできる。
pip install azure-cognitiveservices-speechそして以下のプログラムを「speech-text.py」という名前で保存しよう。なお、下記の(*1) のAPI_KEYにはAzure Portalで取得したキーを指定する必要がある。
import azure.cognitiveservices.speech as speechsdkimport time, sys# Azure Portal で取得したキーと地域を指定 --- (*1)API_KEY = "*******"API_REGION = "japaneast"def recognize(file):# APIの設定 --- (*2)speech_config = speechsdk.SpeechConfig( subscription=API_KEY, region=API_REGION)# 言語を日本語に指定speech_config.speech_recognition_language="ja-JP"# WAVファイルを指定audio_config = speechsdk.AudioConfig(filename=file)# SpeechRecognizerを生成 --- (*3)recog = speechsdk.SpeechRecognizer( speech_config=speech_config, audio_config=audio_config)# イベント管理用変数を初期化 --- (*4)done = Falsetext = ""# コールバック関数を定義def stop_cb(evt): # 終了した時 nonlocal done done = Truedef recongnized(evt): # 認識した時 nonlocal text text += evt.result.text print("recognized:", evt.result)# 音声認識のイベント設定 --- (*5)recog.recognized.connect(recongnized)recog.session_stopped.connect(stop_cb)recog.canceled.connect(stop_cb)# 音声認識を実行 --- (*6)recog.start_continuous_recognition()# 音声認識が終わるまで待機 --- (*7)while not done: time.sleep(0.5)recog.stop_continuous_recognition()return text# 処理を実行 --- (*8)if __name__ == '__main__':if len(sys.argv) < 2: print("python speech-text.py (file)"); quit()infile, outfile = sys.argv[1], sys.argv[1] + ".txt"text = recognize(infile)print("結果:", text)with open(outfile, "wt", encoding="utf-8") as fp: fp.write(text)プログラムを保存したら、コマンドラインで以下のコマンドを実行することで音声ファイルを音声認識してテキストファイルに変換できる。例えば、「test.wav」という名前のファイルを変換するには以下のようなコマンドを実行する。正しくコマンドが実行できると、「test.wav.txt」というテキストファイルが生成される。なお、macOSの場合は「python」を「python3」と置き換えよう。
$ python speech-text.py test.wavプログラムを確認してみよう。既に紹介したように(*1)の部分でAzure Portalで指定したキーと地域を指定しよう。(*2)の部分では音声認識APIを使うための設定を行う。
(*3)では(*2)で行った設定を引数に指定してSpeechRecognizerオブジェクトを生成する。SpeechRecognizerでは音声認識を実行した時点で、コールバックイベントが実行される仕組みになっている。そこで、(*4)の部分でコールバックイベントの準備をし、(*5)でコールバックイベントの設定を行う。
(*6)で音声認識を実行したら、(*7)の部分でtime.sleep関数を利用して実行完了まで繰り返し待機する。
(*8)ではコマンドライン引数を得て音声認識のrecognize関数を実行をしてファイルに変換後のテキストを保存するようにした。
まとめ
以上、今回はMicrosoftの音声認識APIを利用する方法を紹介した。なお、手元で試したところ、音声認識の結果は録音状態に左右されるものの、はきはきとマイクに向かってしゃべったものであれば、だいたい問題なく認識することができた。思ったよりも手軽に使えるので活用してみよう。







